Pablo Díaz Viñambres
MSc Informatics @ TUM
Efficient Neighbourhood Search in 3D Point Clouds Through Space-Filling Curves and Linear Octrees
Este es mi primer artículo de investigación, escrito en colaboración con Miguel Yermo, Ph.D., Silvia R. Alcaráz, Ph.D., Óscar G. Lorenzo, Ph.D., Francisco F. Rivera, Prof. y José C. Cabaleiro, Prof., y disponible como preprint en arXiv. Se desarrolló como una continuación y ampliación de mi TFG en Ingeniería Informática. La librería desarrollada en C++ también está disponible como código abierto en GitHub.
Abstract (traducido del original)
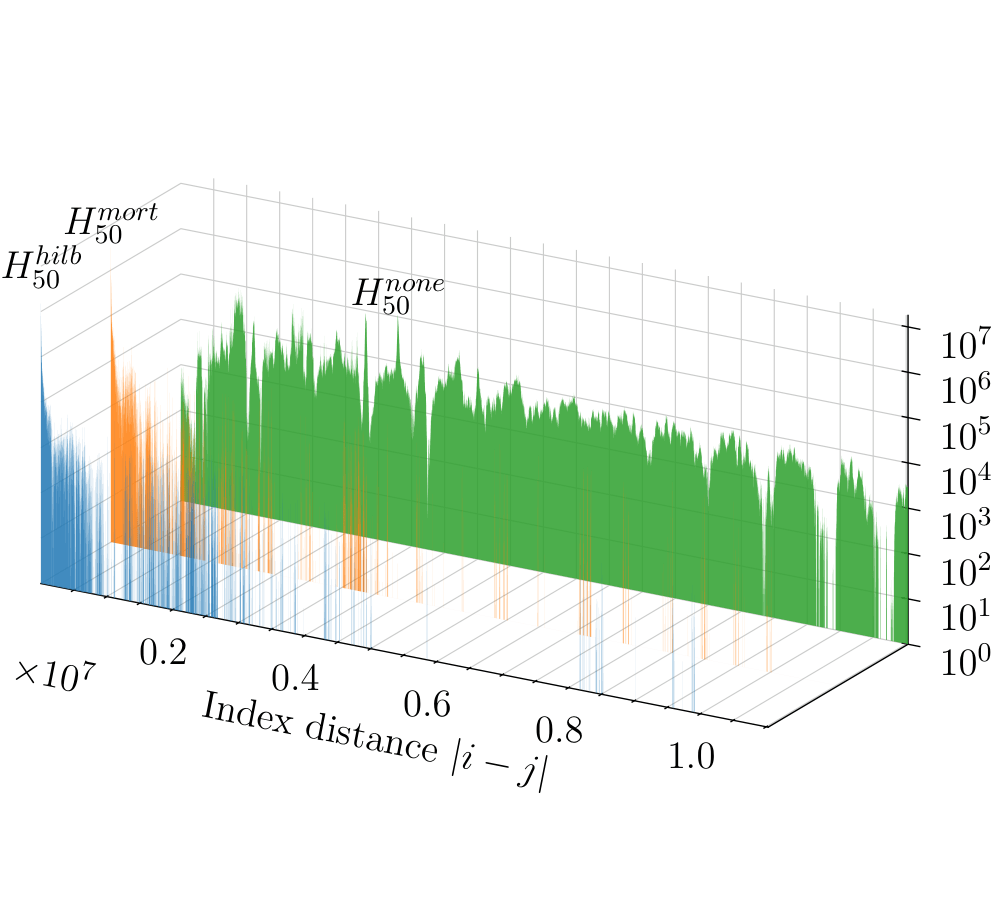
Este trabajo presenta un enfoque eficiente para la búsqueda de vecindades en nubes de puntos 3D, combinando una reordenación espacial basada en Space-Filling Curves (SFC), concretamente en las curvas de Morton y Hilbert, con una implementación de octree lineal. También proponemos algoritmos de búsqueda especializados para consultas de radio fijo y kNN, basados en octrees lineales. Además, introducimos el concepto de histograma de localidad kNN, que puede emplearse para caracterizar la localidad en los accesos a datos, y que observamos que está directamente relacionado con los fallos caché y el rendimiento de las búsquedas. Nuestros experimentos revelan que la reordenación mediante SFC mejora significativamente el acceso a datos espaciales, reduciendo el número de fallos caché entre un 25% y un 75% y el tiempo de ejecución hasta en un 50%. Asimismo, comparamos nuestra propuesta con varias implementaciones de octree y KDTree ampliamente utilizadas. Nuestro método logra una reducción significativa del tiempo de búsqueda, siendo hasta 10 veces más rápido que las soluciones existentes. Además, analizamos el rendimiento de nuestras búsquedas de vecindad (paralelizadas con OpenMP), demostrando alta escalabilidad con el número de núcleos y el tamaño del problema. En particular, observamos un speedup de hasta 36x al ejecutar búsquedas de radio fijo en un sistema con 40 núcleos. Los resultados obtenidos indican que nuestros métodos proporcionan una solución robusta y eficiente para aplicaciones que requieren acceso rápido a conjuntos de vecinos 3D a gran escala.
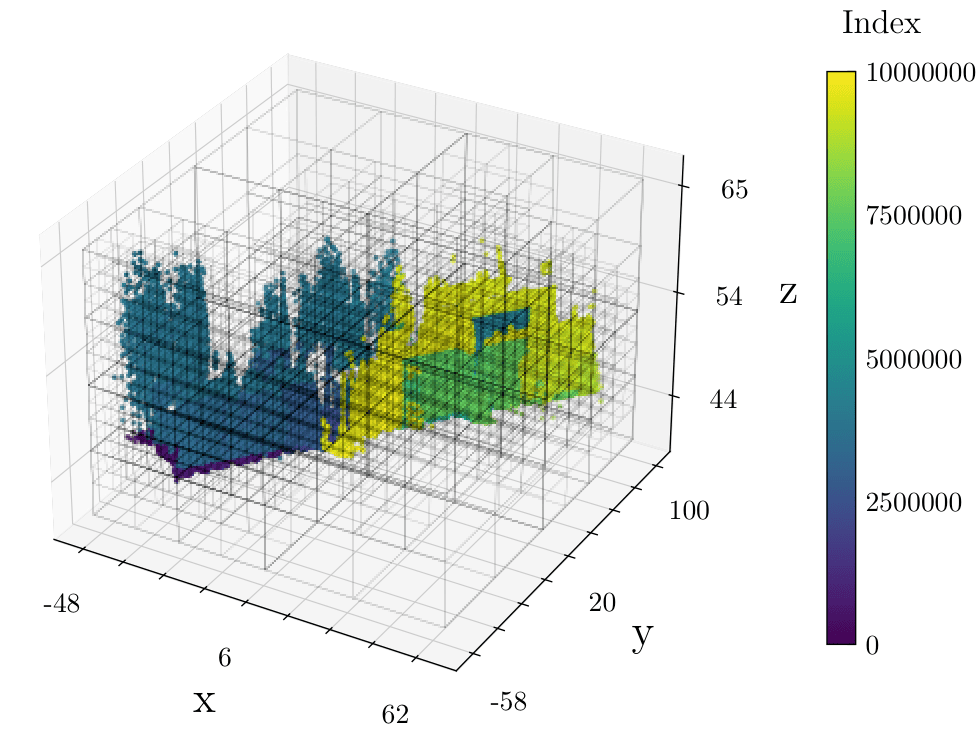
Estudio y mejora del rendimiento de modelos Octree para búsqueda de vecinos en nubes de puntos 3D
Para mi TFG de Ingeniería Informática, desarrollé algoritmos rápidos para consultas espaciales en nubes de puntos 3D . El problema que abarqué es sencillo: dado un centro , o bien buscamos todos los puntos a menos de una distancia dada (fixed-radius queries), o bien buscamos los puntos más cercanos (kNN queries) de la nube. Estas dos operaciones de búsqueda de vecindad son extremadamente comunes, y suelen convertirse en un cuello de botella computacional en el procesado de nubes grandes para teledetección y fotogrametría. Para resolver este problema, desarrollamos dos enfoques para acelerar las búsquedas:
- Reordenación de la nube de puntos mediante Space Filling Curves (SFCs), alterando el orden en memoria para reducir fallos de caché y mejorar el rendimiento hasta un 75%.
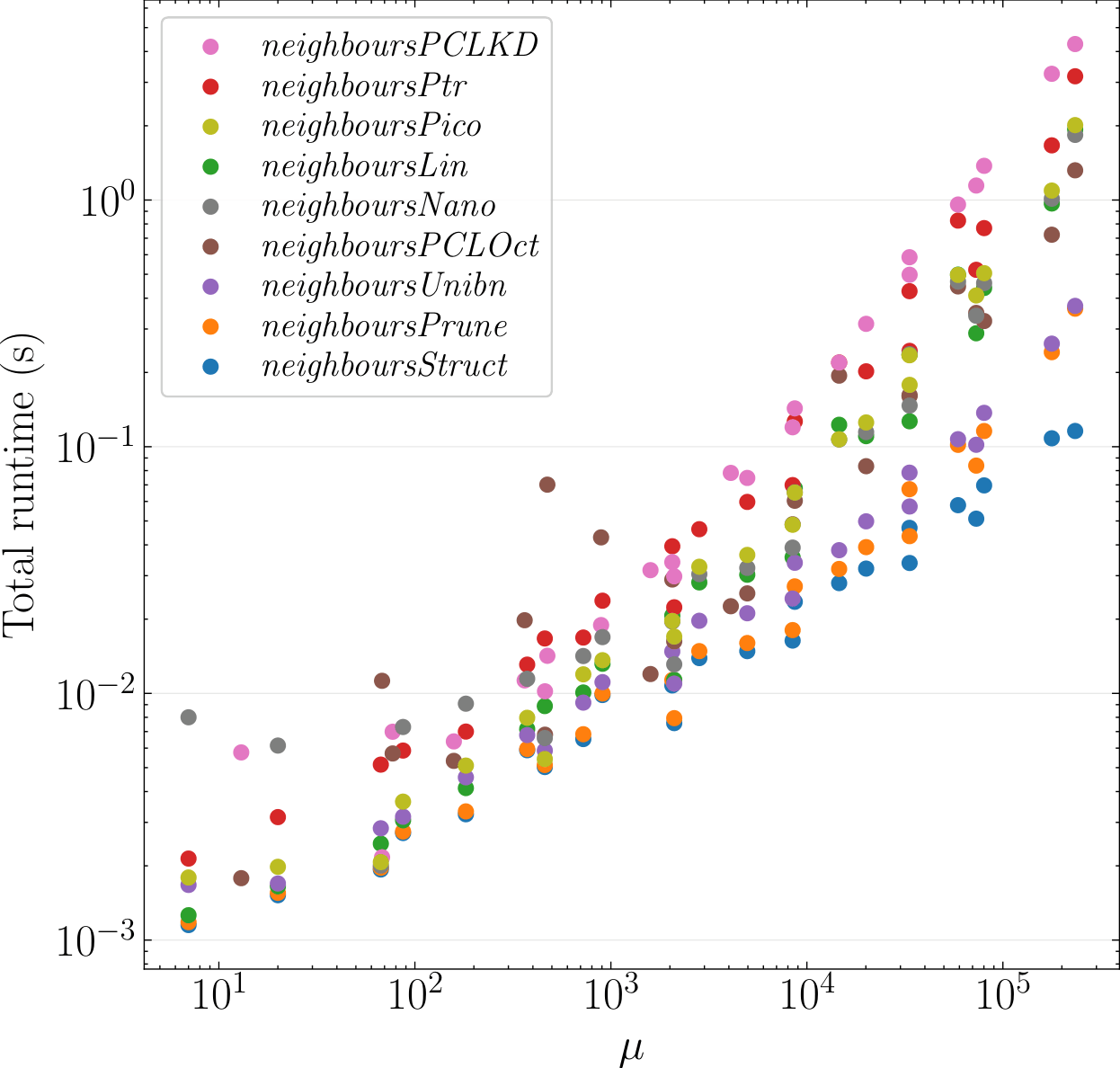
- Una estructura de datos en forma de octree linear, equipada con un algoritmo novedoso para recuperación rápida de puntos en búsquedas de radio fijo, y una adaptación a esta estructura de un algoritmo conocido para búsquedas kNN. Ambos algoritmos destacan en rendimiento y superan incluso bibliotecas SoTA en términos de velocidad de las búsquedas (hasta 10x más rápido, mejor escalabilidad en y ), uso de memoria (70% menos, layout compacto) y tiempo de construcción (paralelizable, hasta 30x más rápida).
El trabajo obtuvo la nota máxima (10/10) y fue reconocido con Matrícula de Honor como uno de los mejores de la promoción. Tras mi graduación, mis tutores y yo seguimos trabajando en el proyecto y lo ampliamos primero a un artículo corto para las Jornadas SARTECO 2025. Más adelante, redactamos un artículo completo, ya enviado y disponible como preprint en arXiv. Consulta la entrada del proyecto de investigación para más información!.
La Transformada Rápida de Fourier
El tema que escogí para mi TFG de Matemáticas fue la Transformada de Fourier, una herramienta matemática que me fascina desde hace años y que quería estudiar a fondo. Este trabajo comienza con una recopilación de resultados importantes sobre espacios , en particular , donde definimos por primera vez la Transformada de Fourier (FT) continua. Después demostramos el teorema de Plancherel para su extensión a y apuntamos la construcción y propiedades de la FT multidimensional.
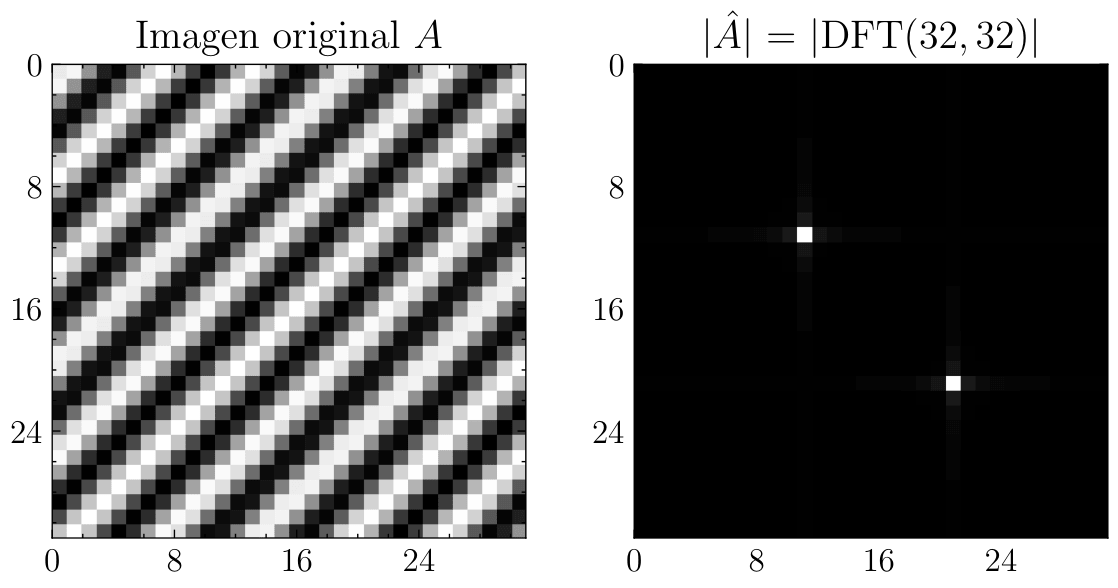
En la segunda parte del trabajo, desarrollamos un marco matemático sólido para la Transformada Discreta de Fourier (DFT). Esta DFT puede entenderse como un muestreo de una FT continua, y se define de forma limpia mediante raíces de la unidad y matrices de Fourier. Una vez definida la DFT, podemos introducir algoritmos de Tranformada Rápida de Fourier (FFT) para su cálculo. Primero presentamos el conocido algoritmo Cooley-Tukey, tanto en su variante Decimation-In-Time (DIT) como Decimation-In-Frequency (DIF), que aplican la idea de divide y vencerás para reducir la complejidad del cálculo de una DFT de puntos desde a , para . Esto permite realizar convoluciones muy rápidas en el dominio de la frecuencia mediante el discrete convolution theorem. También existen otros algoritmos FFT, como split-radix FFT y Rader o Bluestein FFT para primo.
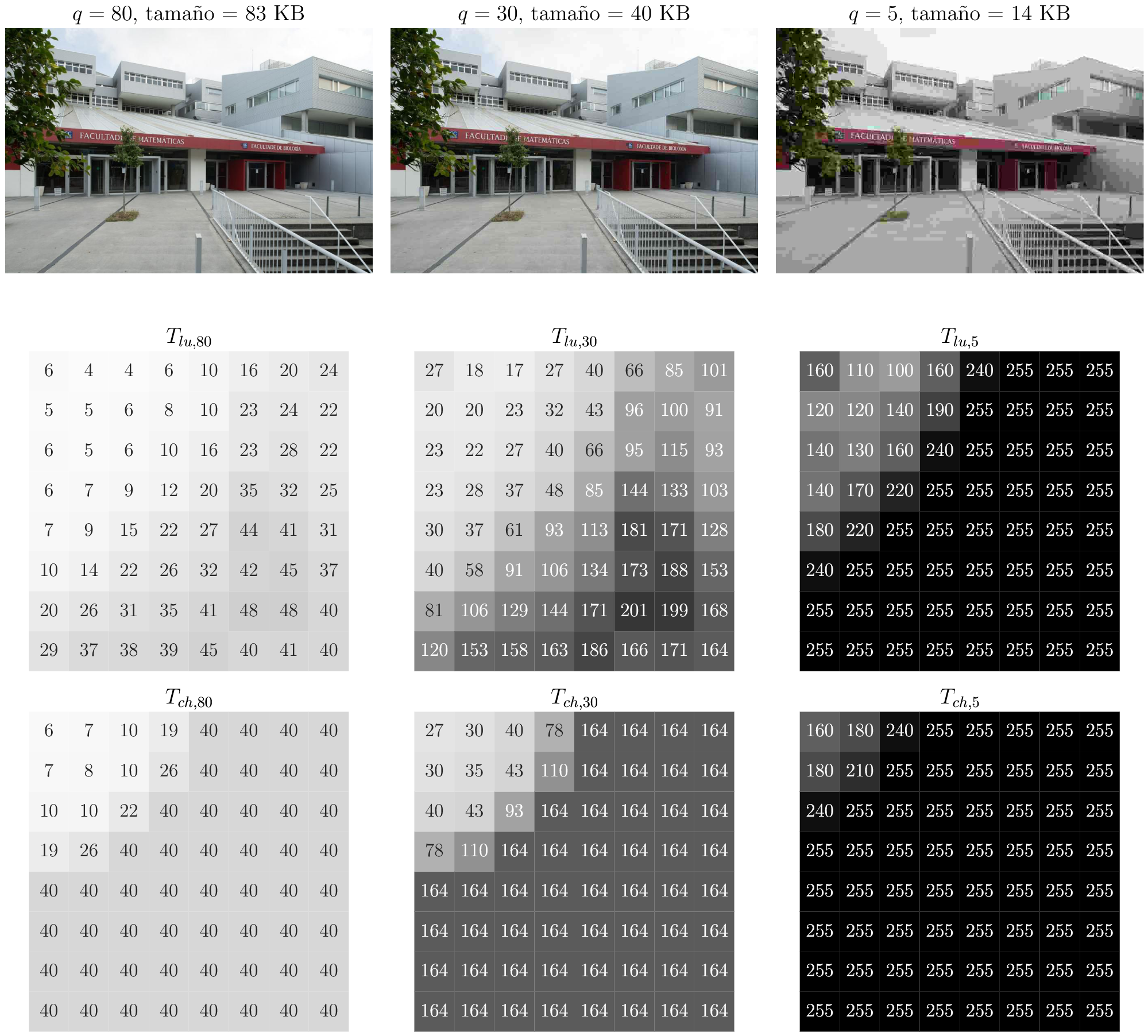
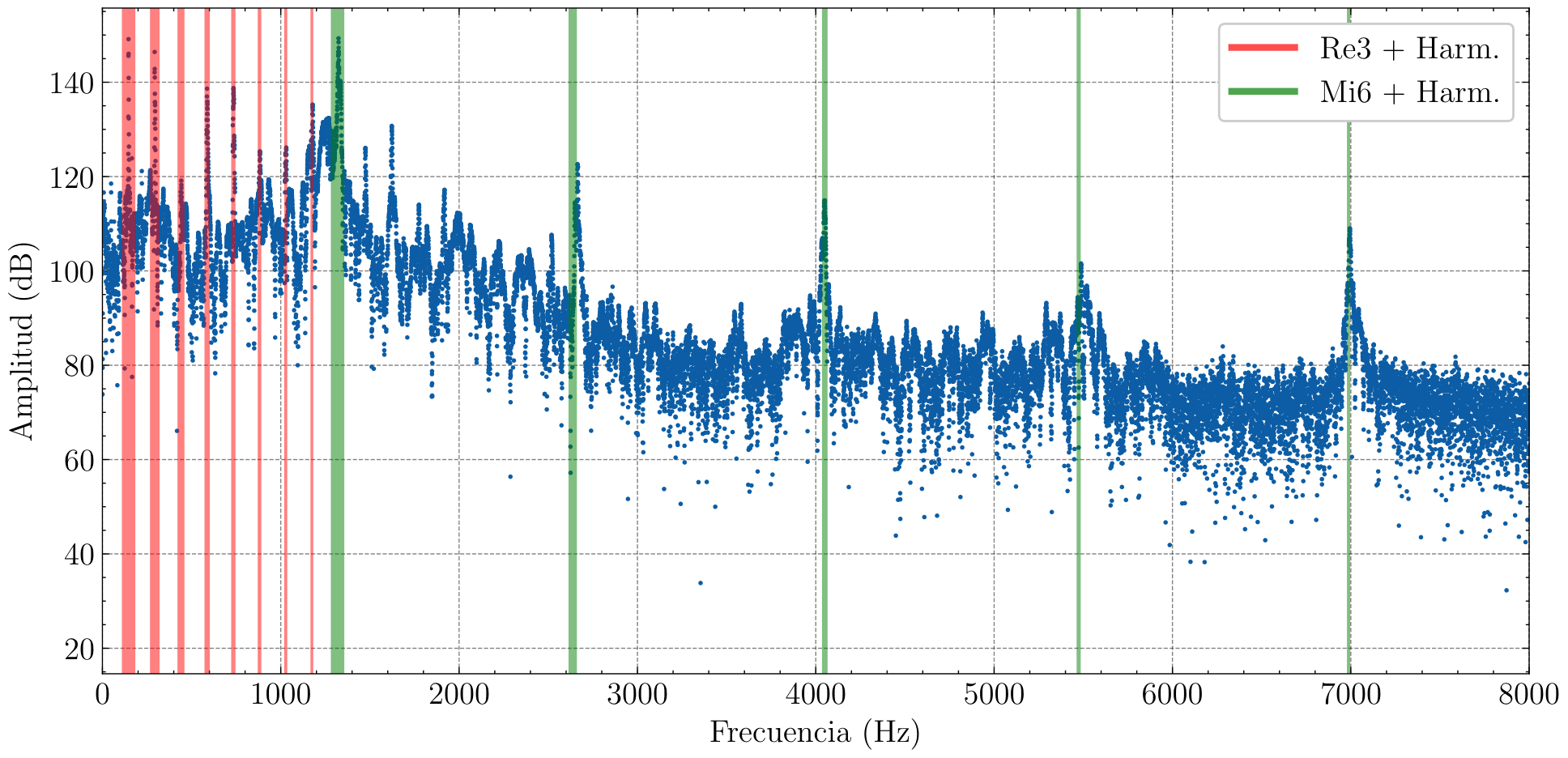
Para cerrar el trabajo, repasamos aplicaciones importantes en procesamiento de señales (filtros low-pass, high-pass y band-pass, análisis espectral de acordes de guitarra) y compresión de imágenes (formato JPEG). El trabajo obtuvo una nota sobresaliente (9.8/10). En conjunto, aprendí muchísimo y disfruté mucho escribiendo esta tesis. Muchas gracias a Lucía López Somoza por su excelente supervisión!
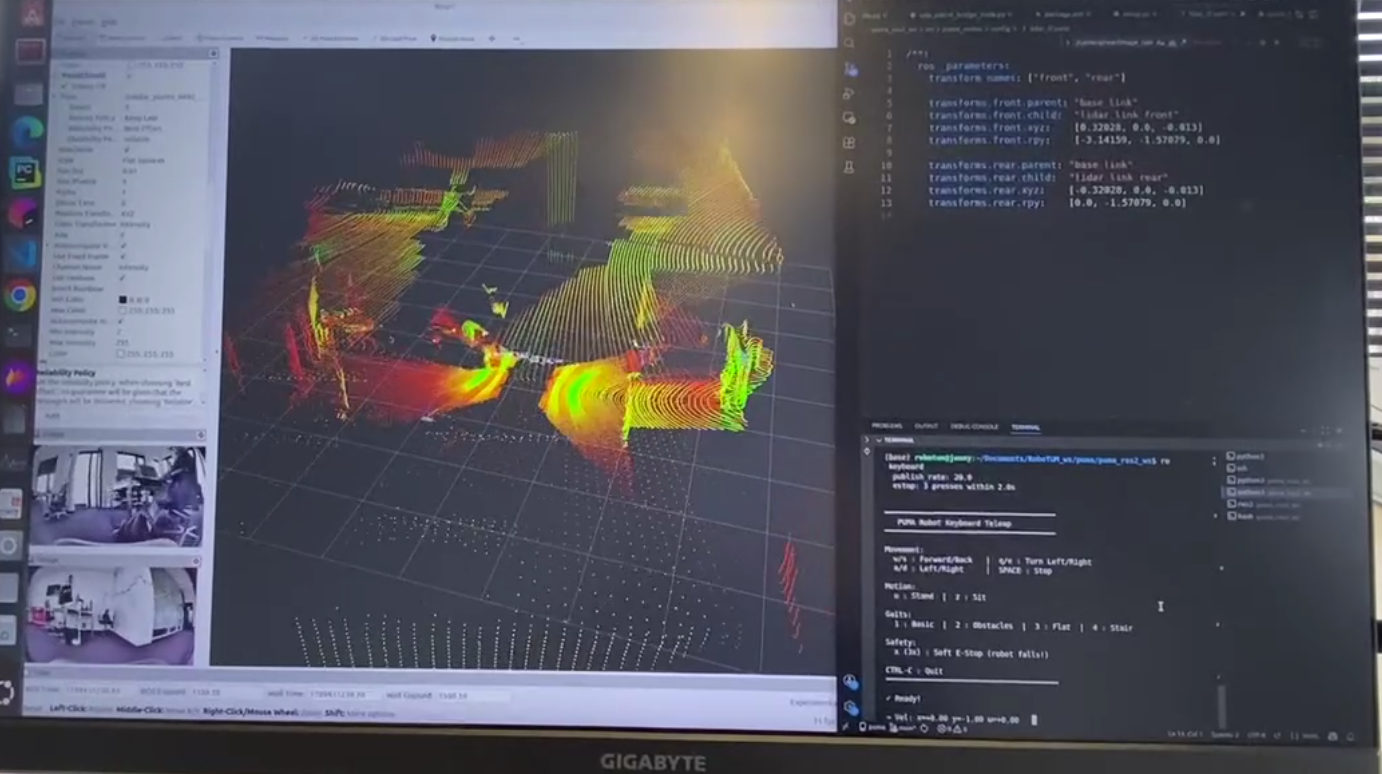
Proyecto PUMA

Junto con miembros de RoboTUM y Maxwell Robotics, desarrollamos un stack de software para el robot cuadrúpedo M20 Lynx de Deep Robotics. Este modelo viene originalmente con un stack propietario difícil de extender, así que reescribimos el software desde cero para mejorar sus capacidades. Primero construimos una capa de interfaz de bajo nivel en ROS2 que interactúa con la telemetría del robot, envía comandos de movimiento y lee los flujos de datos provenientes de las dos cámaras y sensores LiDAR. Sobre esta base, desarrollamos un stack de autonomía para el mapeado y la navegación por waypoints. Este fue mi primer proyecto como miembro de RoboTUM y una gran forma de empezar en el mundo de la robótica!
Curso de introducción a Python y su uso en el análisis de datos
Durante nuestro último cuatrimestre en la Universidade de Santiago de Compostela, Xiana Carrera y yo decidimos colaborar junto a la facultad de Matemáticas organizando un curso de competencias auxiliares. Nos centramos en uno de los temas que no se cubren en el currículum del Grado en Matemáticas, pero que es fundamental para muchos de sus estudiantes: La programación en Python y el Análisis de Datos.
Los contenidos del curso se diseñaron con mucho detalle para poder enseñar lo máximo posible en 8 sesiones, con un total de 16 horas lectivas, de forma entretenida para todos. Programamos diapositivas interactivas en reveal.js para que el alumnado pudiera seguir la clase en directo. Los temas incluyeron una introducción a las estructuras básicas de programación en Python (control de flujo, functions, tipos de datos, I/O, lambdas, OOP, ) y el uso de paquetes fundamentales para análisis de datos (NumPy, Pandas, matplotlib, seaborn y scikit-learn). Cerramos el curso con un proyecto de análisis de datos sobre la correlación entre el gusto musical y los rasgos psicológicos de una persona.
En conjunto, el curso despertó mucho interés: tuvimos que seleccionar 30 estudiantes entre más de 100 solicitudes, y en una encuesta de satisfacción posterior nuestros alumnos destacaron la calidad de la docencia impartida y de los materiales que preparamos.
Lo que la geometría no te cuenta: la cuadratura del círculo
Los Premios Emmy Noether fueron un concurso de divulgación matemática en YouTube organizado en 2023 por el popular youtuber Mike Mates. Decidí participar junto con Xiana Carrera y crear un vídeo sobre el problema clásico de la cuadratura del círculo.
Después de cursar en el cuatrimestre anterior una asignatura de Teoría de Galois, en la que aprendimos sobre temas como la irresolubilidad algebraica de las ecuaciones de quinto grado y los números construibles, nos motivó preparar una propuesta sobre un problema relacionado. El enfoque consistía en partir de construcciones clásicas con regla y compás, como las que se encuentran en los Elementos de Euclídes, y llegar hasta la teoría de números moderna, en particular a la demostración de que es un número trascendente, lo que prueba la imposibilidad de resolver el problema de la cuadratura del círculo.
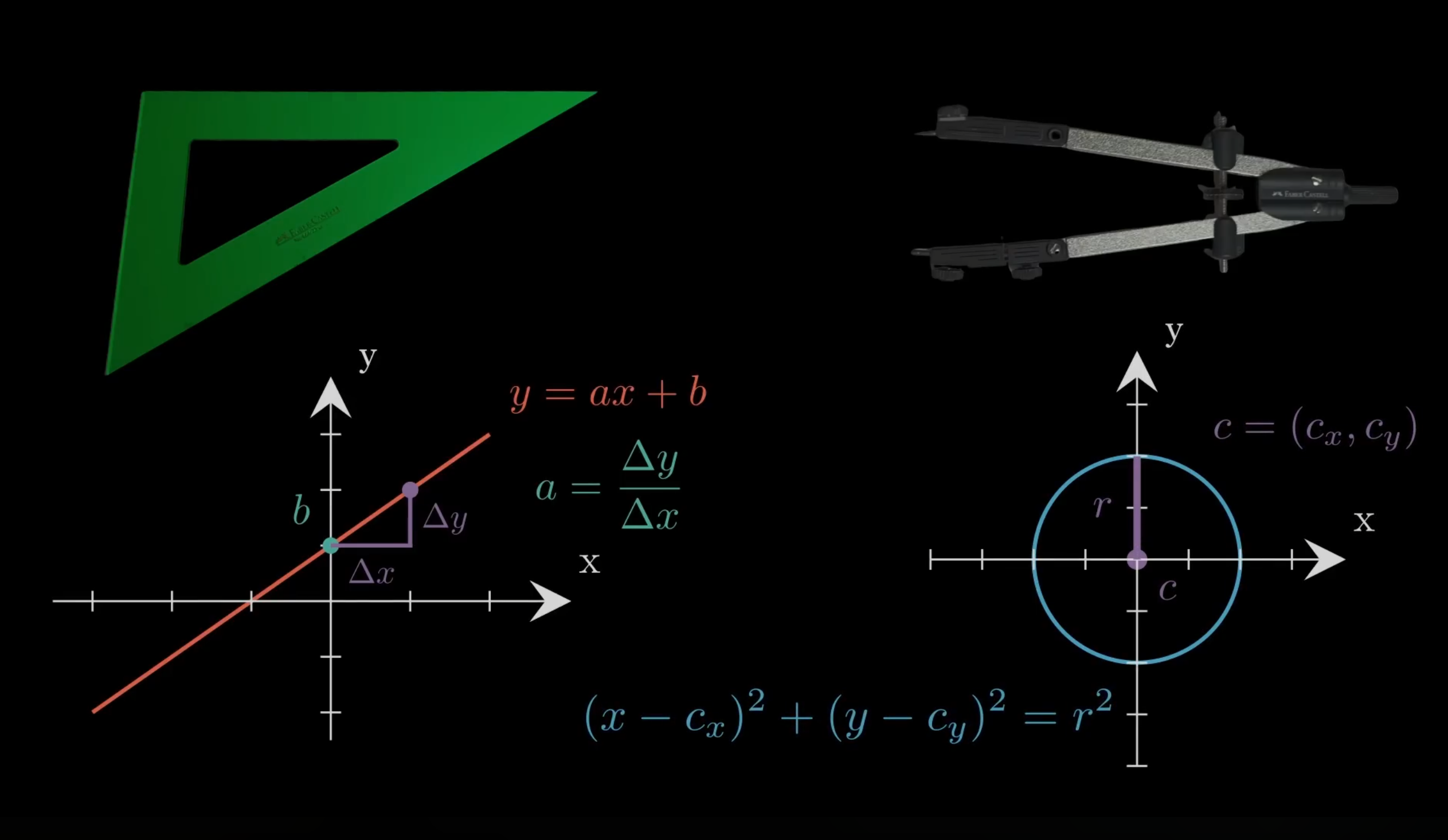
En lo visual, apostamos por un enfoque híbrido, combinando timelapses dibujando con regla y compás reales con animaciones hechas con la librería manim de 3blue1brown.
Para nuestra sorpresa, el vídeo fue un éxito! Ya acumula más de 137.000 visualizaciones y fue premiado como uno de los ganadores del concurso. Sin embargo, para nosotros la mayor recompensa fue el gran número de comentarios positivos y la sensación de haber inspirado a mucha gente joven interesada en las matemáticas.
Zone+
Para HackaTUM 2025, formé un equipo con David Atanasoski, Vinicius Agreste Martines dos Santos y Merve Öztekin para participar en el track de Logitech y construir un plugin de bienestar para el ecosistema Logitech Actions+. El plugin incluía interacciones con webcams, ratones con sensor háptico y el panel de entrada Options+. Incorporamos varias funcionalidades, entre ellas:
- Seguimiento del tiempo dedicado a redes sociales.
- Gestión de tareas de Notion.
- Recordatorios de nivel de energía y estiramientos.
- Temporizador Pomodoro.
- Detección de somnolencia.
Aunque no obtuvimos ningún premio en la track, fuimos uno de los equipos shortlisteados, y disfrutamos muchísimo construyéndolo durante un fin de semana realmente intenso.
University Hack 2024
Para esta competición de análisis de datos, mis compañeros Pablo Landrove Pérez-Gorgoroso, Xiana Carrera y yo desarrollamos una pipeline end-to-end para predecir el rendimiento de producción en la fabricación de antígenos en biorreactores. El reto consistía en tomar conjuntos de datos grandes y desestructurados, desde logs generales de lotes hasta lecturas de sensores de alta frecuencia, y transformarlos a un formato unificado para entender qué factores impulsan realmente un cultivo exitoso.
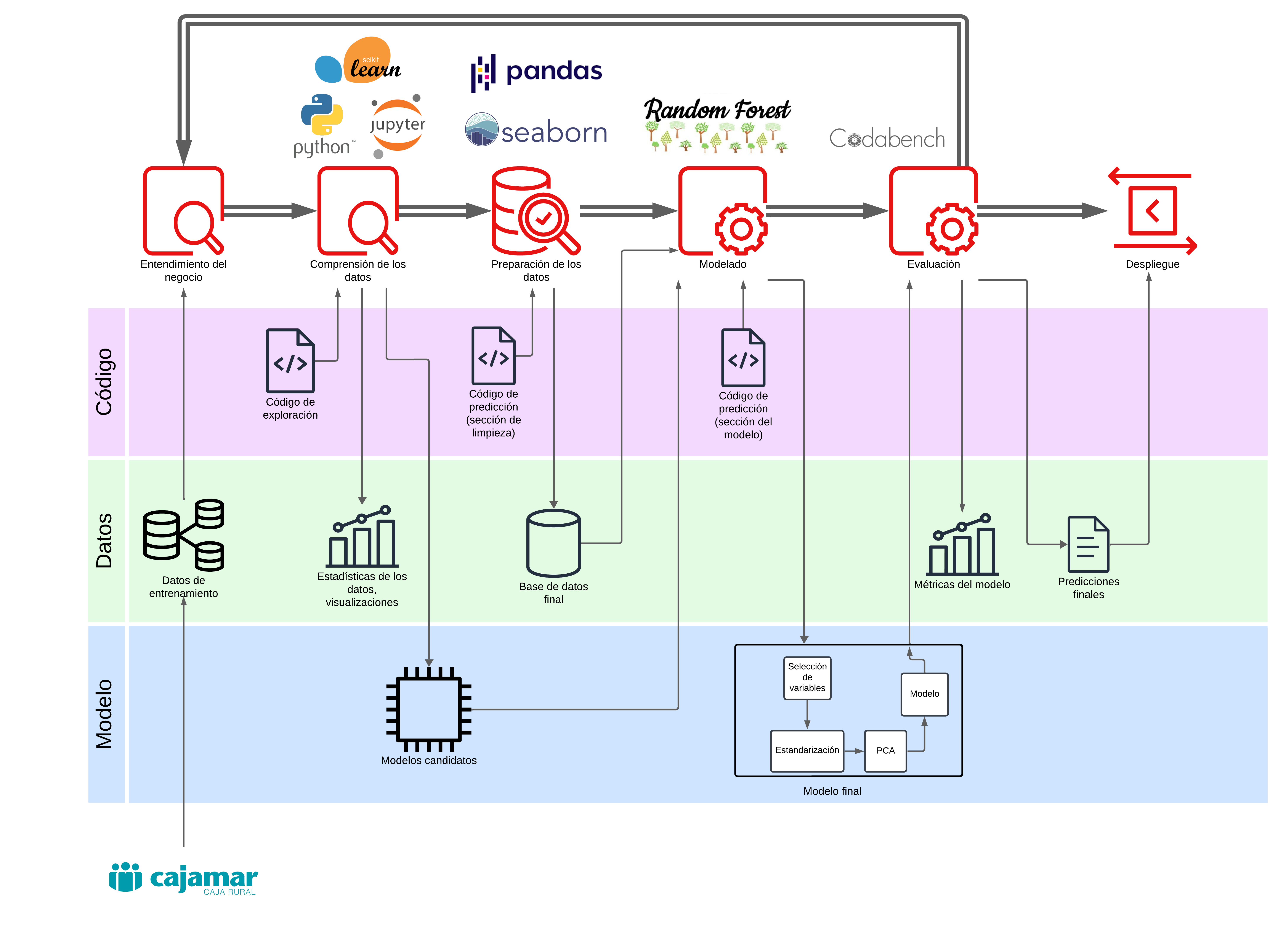
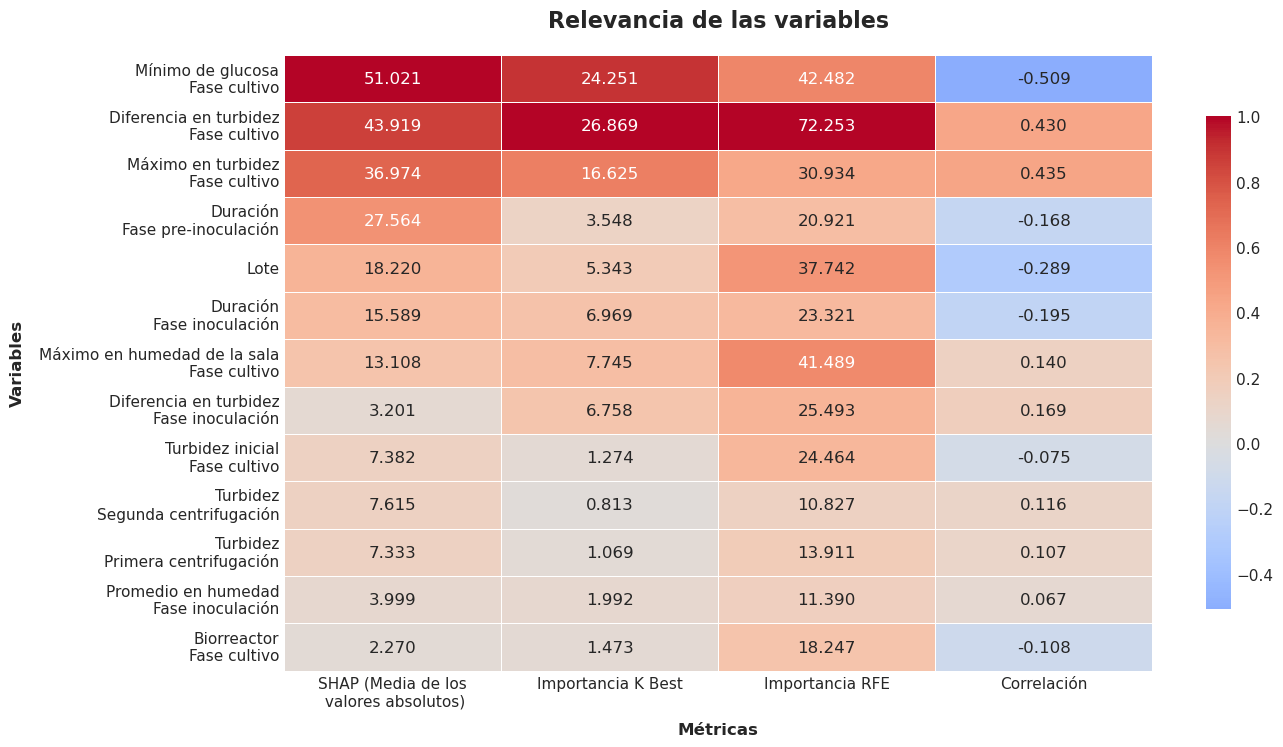
Primero limpiamos los datos a través de varias fases de fabricación (pre-inoculación, inoculación y cultivo final) y seleccionamos las variables más relevantes para explicar la producción. Después entrenamos un modelo de machine learning predictivo para estimar los rendimientos y aplicamos herramientas de interpretabilidad para explicar los resultados. Vimos que factores como los niveles mínimos de glucosa, cambios en la turbidez del fluido e incluso la humedad ambiental de la sala de cultivo estaban entre los predictores más fuertes del éxito del proceso.
Nuestro equipo consiguió el primer puesto en la fase local de la USC y se clasificó para la fase nacional. A nivel personal, este proyecto me ayudó a profundizar mucho en modelos clásicos de Machine Learning y en workflows de análisis de datos complejos.
Sentikelia
Sentikelia fue nuestro proyecto ganador en el track de Kelea en HackUDC 2025. Este proyecto fue desarrollado junto a Pablo Landrove Pérez-Gorgoroso, Nicolás Rosales Gómez y Robert Ostrozhinskiy. Nuestro objetivo era crear un asistente digital comprensivo que ofreciera un espacio seguro para la autorreflexión, construyendo además un perfil psicológico dinámico. Con esta información, la aplicación proporciona recomendaciones personalizadas, actuando como un coach virtual que guía a las personas en sus pensamientos y ayuda a detectar patrones de salud mental a largo plazo. Algunas funcionalidades clave son:
- Diario virtual: un diario intuitivo para registrar pensamientos, emociones y experiencias personales de forma segura.
- Análisis de personalidad: evaluación continua de las entradas para comprender estados emocionales y rasgos de personalidad a lo largo del tiempo.
- Coach Virtual: recomendaciones prácticas y personalizadas basadas en la evolución del perfil psicológico.
- Autoreflexión mediante IA: uso de inteligencia artificial para analizar registros pasados y lanzar preguntas relevantes que fomenten una autorreflexión más profunda.

El proyecto se construyó con un stack moderno: frontend con Vite y TailwindCSS, backend con FastAPI sobre Uvicorn y base de datos con MongoDB y PyMongo. Los modelos de IA que usamos son gpt-4o-mini, como LLM de propósito general, y modelos BERT finetuneados para análisis de personalidad y sentimiento.

Tabster
Tabster fue un proyecto de desarrollo web full-stack realizado para la asignatura Software Atelier 3: The web durante nuestro Erasmus en la USI. Nuestro equipo, formado por Pablo Landrove Pérez-Gorgoroso, Elvira Baltasar, Vladyslav Kotov, Guglielmo Daniele Mazzesi, Eduard Bilous y yo, desarrolló una web para renderizar, subir y reproducir tablaturas de guitarra interactivas, intentando recrear y ampliar las ideas de la popular plataforma Songsterr.
La idea del proyecto fue propuesta por Pablo Landrove y yo al profesor Cesare Pautasso. Ambos somos guitarristas y nos apetecía construir algo relacionado con uno de nuestros hobbies. Tras un par de meses de trabajo intenso, conseguimos un diseño coherente y limpio, con buen rendimiento y una interfaz fácil de usar.
Tabster fue uno de los proyectos de clase con los que más he disfrutado, tanto durante el desarrollo como con el resultado final, y me enseñó muchísimo sobre software engineering y web development en un contexto real. El proyecto fue seleccionado como uno de los mejores de la clase, y presentado frente a cientos de personas durante el día de la facultad!